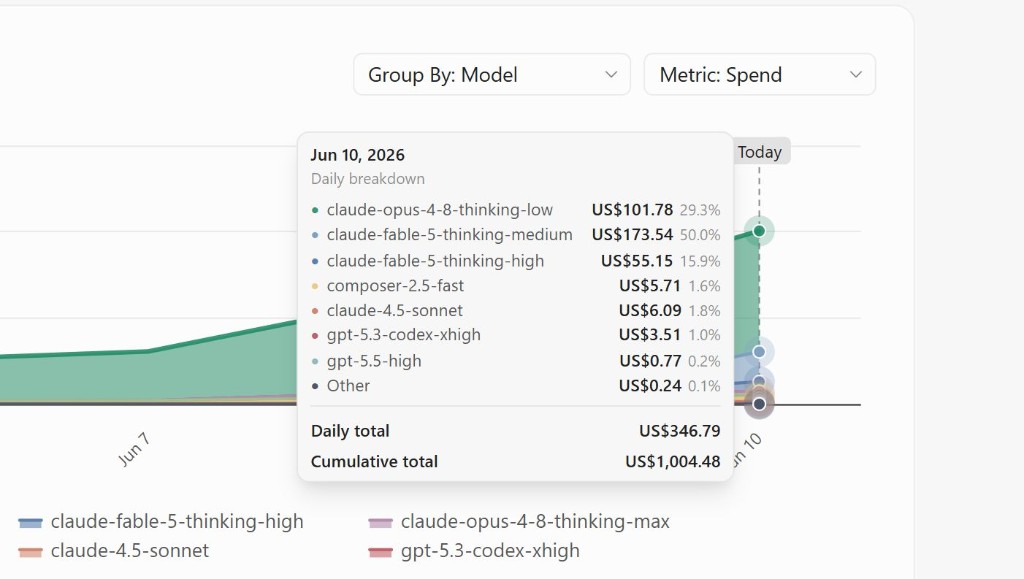
That screenshot above is my Cursor AI spending dashboard from a single day. $346.79. Cumulative total for the week: $1,004.48.
Here's why I did it, what I found, and the framework I now use to decide which AI model gets which job.
What is Claude Fable 5, exactly?
Anthropic just released Claude Fable 5, the first "Mythos-class" model available to the public. Mythos is the model Anthropic considered too capable for general release. It is so good at finding and exploiting security flaws that they initially restricted it to government cyber defense teams only.
Fable 5 uses the same underlying model as Mythos. The only difference is guardrails on a narrow set of high-risk areas, specifically offensive cyber attacks and bioweapons synthesis. For everyday coding, analysis, writing, and architecture work, you are getting the full underlying capability.
So the obvious question for anyone building real software with AI: is it actually meaningfully better, or is this mostly marketing?
I decided the only honest way to answer that was to run it against real codebases, side by side with Claude Opus 4.8 (currently the best competing model at half the price), and see what happened.
What I actually tested
I ran Fable 5 alongside Opus 4.8 across two complete app codebases: DialCoach, a sales coaching platform built on Next.js and Supabase, and the Olivia GRE tutoring platform. Both have meaningful complexity: auth flows, database logic, third-party integrations, background workers, and real users depending on them.
The tests covered:
- Security review: both models asked to audit each codebase for vulnerabilities
- Complex refactors: restructuring parts of the codebase with multiple interdependencies
- Bug fixing on edge cases that had resisted previous fixing attempts
- Architecture planning for upcoming features
- Code generation for new functionality from a spec
The results, honestly
Security: this is where Fable 5 genuinely separates
This was the biggest surprise. Fable 5 found multiple security vulnerabilities that Opus 4.8 missed entirely. Not minor nitpicks. Real issues: an authorization bypass in one of the API routes, a potential SQL injection vector in a dynamic query, and a missing rate-limit on a sensitive endpoint that could have been abused.
This makes sense. The Mythos model was specifically trained and selected for its ability to find security flaws. That capability is not diminished in Fable 5. If anything, the security review use case alone may justify the price for production applications.
Opus 4.8 flagged the obvious things. Fable 5 found the stuff I didn't know to look for.
Hard coding tasks: 10 to 15% better, but not magic
On benchmarks, Fable 5 is roughly 10 to 15% ahead of Opus 4.8 on hard coding tasks, and close to 2x ahead on the very hardest ones. In practice, that difference is real but not always visible. For straightforward code generation and simple refactors, both models get there. The gap shows up on problems with high complexity, many moving parts, or subtle edge cases.
It is also worth saying: neither model is magic. Both still need iteration, clear context, and re-prompting on the trickier things. Fable 5 needs fewer rounds on average, and its first attempts tend to be more complete. But the expectation that you can hand it a vague prompt and get perfect code back is still going to disappoint you.
The cost: exactly double
Fable 5 costs $10 per million input tokens and $50 per million output tokens. Opus 4.8 is $5 and $25. That is exactly double, with no exceptions. Here's what my actual week looked like:
| Model | Daily spend (10 Jun) | Share |
|---|---|---|
| Fable 5 (medium thinking) | $173.54 | 50.0% |
| Opus 4.8 (low thinking) | $101.78 | 29.3% |
| Fable 5 (high thinking) | $55.15 | 15.9% |
| Claude 4.5 Sonnet | $6.09 | 1.8% |
| Composer 2.5 Fast | $5.71 | 1.6% |
| GPT-5.3 Codex | $3.51 | 1.0% |
| Other | $1.01 | 0.3% |
| Daily total | $346.79 | 100% |
The $1,000 cumulative total across the week reflects a heavy testing period. I was deliberately throwing everything at both models to get a clear comparison. Normal weekly spend running production AI tools is significantly lower.
Want AI tools that actually run your business tasks? From chatbots to automations to full apps, I build the systems, you keep the savings. No token bills for you.
Book a free 15-min call →When to use Fable 5 vs Opus 4.8
The smartest move is not picking one model. It is routing the right task to the right model, the same way you would not use a sledgehammer to hang a picture frame.
After a week of side-by-side testing, here is where I land:
Use Fable 5 for:
- Security reviews on any codebase that has real users or real data. This is the clearest win.
- Complex refactors across many files with interdependencies, where getting it wrong creates hours of cleanup.
- Hard bugs that have already resisted one or two rounds of fixing. Fable 5 reasons through them more systematically.
- Architecture decisions for anything that will be load-bearing. Its ability to hold large context and reason about tradeoffs is noticeably better.
Use Opus 4.8 for:
- Routine code generation from clear specs. Fast, reliable, half the price.
- Drafting and iteration where you are going back and forth. The cost difference compounds fast on high-volume sessions.
- Anything where the stakes of a missed edge case are low and you can review the output yourself.
- Exploration and prototyping before you commit to a direction.
Honest verdict
Fable 5 is genuinely better, especially on security and the hardest coding problems. But it is not 2x better for most tasks, and it costs exactly 2x more. The right answer is not "always use the best model." It is building a routing habit: high-stakes work goes to Fable 5, everything else goes to Opus 4.8. That is roughly what happened naturally across my week, and it is the approach I'd recommend to anyone building seriously with AI.
What does this mean if you are not a developer?
If you run a business and you are using tools like Claude.ai or ChatGPT directly, the main thing to know is this: the models have gotten meaningfully better. The work AI can reliably do today, writing, analysis, summarising, building first drafts of things, is broader and more accurate than it was six months ago.
The nuanced part, knowing which model to use for which task, is exactly the kind of thing that gets optimised when you work with someone who lives in this stuff daily. If you are curious about getting AI actually working inside your business rather than just experimenting with it, that is what I build.
Want AI systems built properly for your business?
I build custom AI chatbots, automations, and apps for small businesses. Melbourne-based, working worldwide. I handle the models, the tokens, and the complexity. You just see the results.
Book a free 15-min call